1.前提
a. flume 收集–》flume 聚合–》kafka ,启动进程和启动kafka manager监控,参考08【在线日志分析】之Flume Agent(聚合节点) sink to kafka cluster
b.window7 安装jdk1.7 或者1.8(本次环境是1.8)
c.window7 安装IDEA开发工具(以下仅供参考)
使用IntelliJ IDEA 配置Maven(入门):
http://blog.csdn.net/qq_32588349/article/details/51461182
IDEA Java/Scala混合项目Maven打包:
http://blog.csdn.net/rongyongfeikai2/article/details/51404611
Intellij idea使用java编写并执行spark程序:
http://blog.csdn.net/yhao2014/article/details/44239021
2.源代码
(可下载单个java文件,加入projet 或者 整个工程下载,IDEA选择open 即可)
GitHub: https://github.com/Hackeruncle/OnlineLogAnalysis/blob/master/online_log_analysis/src/main/java/com/learn/java/main/SparkStreamingFromKafka_WordCount.java
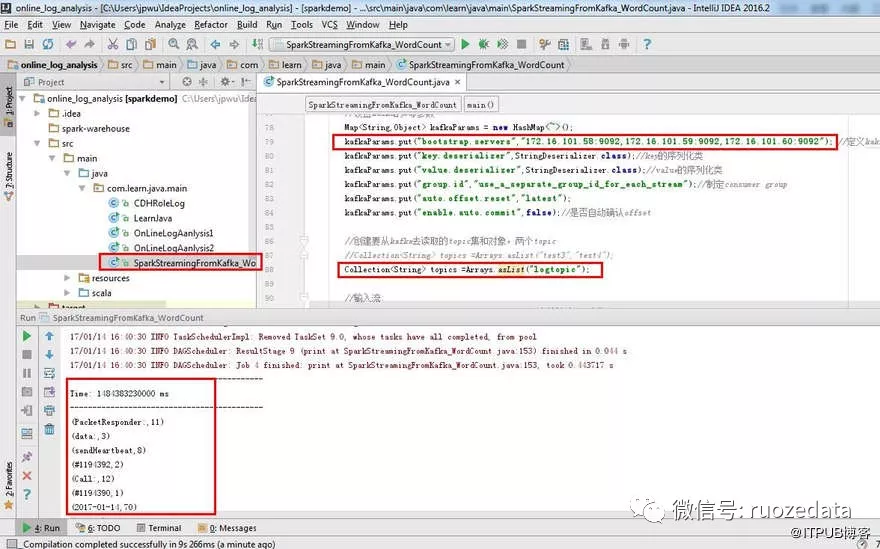
3.使用IDEA 本地运行测试(未打jar包)
海康威视校招电话面试:
1.数据倾斜的解决,怎么知道哪里倾斜
2.自定义类的广播
3.cache机制,rdd和df的cache什么区别
4.spark动态内存,堆内和堆外
5.rdd算子,map,mappartitions,foreach,union
6.宽依赖,窄依赖
7.spark DAG过程,doOnrecive,eventloop执行过程
8.stage和task怎么分类
9.spark调优
10.概念,executor,worker,job,task和partition的关系
11.用没用过spark什么log,没记住
12.讲讲sparkSQL数据清洗过程
13.捎带一点项目
